Real-time Depth Prediction
Contents
- Overview
- Hardware
- Data collection
- Data preprocessing
- Model training
- Robotic deployment
- Future improvements
Overview
Objectives:
- Automated data collection using a mobile robot
- Real-time depth predictions from a webcam
The goal of this project was to train a Convolutional Neural Network (CNN) to perform depth prediction from single images in real-time. By “real-time” I mean that the model should be able to receive images from a webcam feed and make continuous predictions. As an added bonus, I incorporated a robot into the mix and used it to automatically collect RGB-depth image pairs for training as well as demonstrate a live application of real-time depth prediction. This project was done completely in-house (no open source datasets were used) and end-to-end (from data collection to robotic deployment).
Background:
CNNs have been spectacularly effective at numerous computer vision tasks such as object detection (drawing bounding boxes around objects) and image segmentation (pixel-wise classification). Single image depth prediction is similar to image segmentation in that it involves mapping each pixel of an RGB image to a single continuous depth value. Rather than performing a pixel-wise classification of the RGB image, we are doing a regression on each pixel.
Constraints:
- Depth predictions must be predicted directly from a single image (monocular scenario)
- Model inference must be done locally on the robot and cannot use external cloud resources
- Inference speed must be faster than 10 frames per second (technically, real-time is anything greater than 1 FPS but I define real-time to be >10 FPS for aesthetic reasons)
Hardware
For the robot, I used a Turtlebot 2 equipped with an ASUS Xtion Pro 3D sensor and a Jetson TX1 embedded board. The Turtlebot 2 is essentially just a mobile base but is very useful because it has a number of Robot Operating System (ROS) drivers available that allow for easy software integration. The ASUS sensor is capable of capturing depth streams and RGB images at the same time, although there is an offset distance between these captured streams that needs to be calibrated. Finally, the TX1 has an integrated GPU capable of 4 GB of VRAM and has Linux, ROS, and Caffe installed.
Data collection
In order to train a model to map RGB images to depth images I needed to collect example RGB-depth image pairs where the pixels in the RGB image aligned exactly to the depth values in the depth image. The ASUS Xtion Pro 3D sensor has the ability to capture RGB images and depth images at the same but, as I mentioned earlier, there is an offset calibration required in order to align the RGB and depth images exactly since the physical location of each camera is offset by a few centimeters.
Another calibration that was required was removing the “fishbowl” effect of the monocular camera. Since the camera lens is curved, there is a slight curvature in the images that it captures. This is a subtle effect that normally wouldn’t pose issues for most computer vision tasks however since this particular task is sensitive to pixel-to-pixel variations, this is something that could not be ignored. Luckily, this easy to follow tutorial goes through the process of calibrating a monocular camera to remove the fishbowl effect.
Once both of these calibrations were complete, I could use the 3D sensor to capture a variety RGB-depth image pairs simply by placing the sensor in different environments. However, rather than walking around and capturing the image pairs by hand, I decided to put the robot to work and automatically capture the image pairs by driving the robot around and saving image pairs at 5 second intervals. The result was a dataset of 8,079 RGB-depth image pairs with a resolution of 640x480. Here are a few examples from my dataset:


Data preprocessing
These image pairs aren’t bad but you’ll notice that there is quite a bit of white space, which represents NAN, or invalid, values. These NAN values come from two sources: 1) misreadings from the sensor and 2) the alignment shift used to align the depth pixels with the RGB pixels. The first problem arises because the sensor has a minimum and maximum distance with which it can measure depths. Objects too close or too far away from the camera will be misread. This is simply a limitation in the hardware and no explicit solution can be used to fix it. As far as the second problem goes, in order to align the depth map to the RGB image, the whole depth map had to be shifted and the consequence is that a portion of the edges have no measurements. Both of these problems were mostly remedied using a few clever interpolation techniques.
Firstly, depth images with a significant amount of NAN values, say greater than 25%, were thrown out. For the remainder, I applied the following algorithm:
- 2D interpolation to fill the inner NAN values
- Horizontal and vertical linear interpolations to fill the edges x 2 (applied second time to fill corners)
- Smooth interpolated values by applying an average pool
- Fill any remaining NAN values with the mean value of the whole depth image
The code for the data preprocessing is linked here.
The result looks like this:


With cleaned data, another issue with the dataset was the relatively small number of examples. I applied the following data augmentation methods to greatly increase my data set size:
- Random scale up to 50% of the original image size
- Random rotation up to 5 degrees in either direction
- Random flip about the y-axis
- Random HSV shift
- Random contrast multiplier
- Random brightness multiplier
The code for the data augmentation is linked here.
Here’s a before and after example of an RGB-depth image pair going through random augmentation:


Model training
My model architecture is largely based off of the work of Eigen et al. [1] who used a dual-stack CNN:
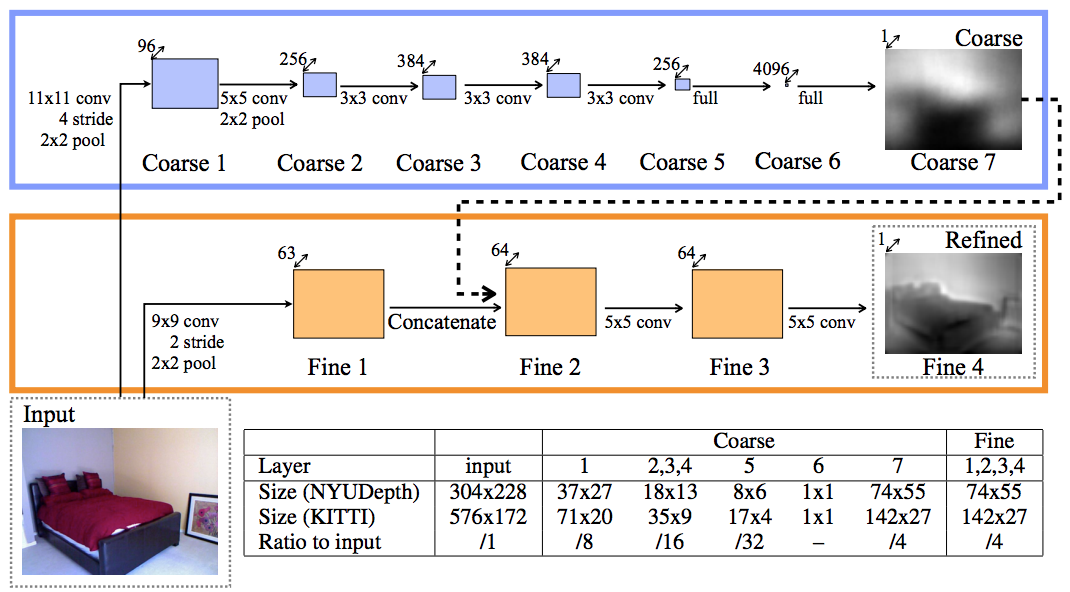
The first CNN stack takes the RGB image as an input and predicts a coarse global-scale depth map at a low resolution. The second CNN stack takes both the RGB image and the coarse prediction as inputs and predicts a finer-scaled depth map. The predictions are scaled up to its original image size using a deconvolutional layer.
My model variation used the 16-layer VGG net as my coarse network with batch normalization layers after every convolutional layer. I also experimented with adding a mean-variance normalization at the output, which leads to much better stability at the output. The downside of using an MVN layer is that the outputs don’t represent true depth values but rather a relative depth map. The input images are also scaled down to a 320x240 resolution.
The code for the model is found here
The model is trained with SGD with a starting learning rate 1e-9 and a batch size of 64. Here are some example model predictions:

Robotic deployment
In order to deploy this model in real-time, the model had to be significantly compressed in order to decrease the computational load. The easiest way to do this is to lower the resolution of the input images and interpolate the output values back to the original size. I trained a much slimmer model with an input resolution of 80x60. I deployed this slimmer model on the TX1 and a video can be found here: video
![]()
There is definitely a delay in the model predictions and the inference speed is not quite the 10 FPS that I had hoped but the overall prediction quality was promising.
Future improvements
One of the biggest limitations of my model was that it used a normalization layer on the outputs in order to stabilize the predictions. The consequence of using this layer is that the depth predictions shown above are only relative depth maps and actual distance measurements cannot be inferred. In order to predict true depth values, the model could be better stabilized with extra CNN stacks that predict different levels of coarseness or by simply collecting more data.
I didn’t spend too much time on optimizing the model for real-time speeds so there are definitely huge opportunities for improvement there. One suggestion could be to use more efficient model architectures such as AlexNet or ResNet. Also, removing slow layers such as batch normalization and any data preprocessing layers could speed up inference.
Overall, this was a fun and fairly successful project and I learned a lot from going through the whole end-to-end process. It’s always fun to get a robot involved in data science.
If you have any questions or suggestions please feel free to contact me.
Citations
[1] D. Eigen, C. Puhrsch, and R. Fergus. Depth Map Prediction from a Single Image using a Multi-Scale Deep Network. In NIPS 2014.