Robotic Face Tracking
Contents
- Overview
- Hardware
- Data collection
- Data preprocessing
- Model training
- Robotic deployment
- Future improvements
Overview
Objectives:
- Develop a face detection model with real-time inference speeds (>10 FPS)
- Develop a face tracking algorithm that controls a motorized webcam to keep detected faces in the center of view
The fields of robotics and machine learning have a natural symbiotic relationship. On one hand, robots benefit from the “intelligence” that comes from machine learning models that allow them to make better decisions and interact more “human-like” whereas machine learning models indulge the spectrum of data that robots can obtain through sensor readings and interactions with people and environments. The collaboration of these two fields is leading to extraordinary possibilities but accomplishing this collaboration is far from simple: one must combine the typical plights of data science while wrestling with the uncooperativeness of hardware.
Nonetheless, in this post I’ll be exploring an application of robotics with deep learning by developing a face tracking system that uses deep learning to detect faces from the robot’s webcam. This project consists of the full end-to-end process of collecting and labelling training data, training the deep learning model, integrating the model into the robotic system, and deploying the system in real-time.
Constraints:
- Model inference must be done locally on the robot and cannot use external cloud resources
- Inference speed must be faster than 10 frames per second (technically, real-time is anything greater than 1 FPS but I define real-time to be >10 FPS for aesthetic reasons)
Hardware
My robotic system consists of a Turtlebot 2 equipped with a Jetson TX1 board and a Logitech QuickCam Orbit AF webcam. The Turtlebot 2 is essentially just a mobile base but is very useful because it has a number of Robot Operating System (ROS) drivers available that allow for easy software integration. The Jetson TX1 board has an integrated GPU with 4 GB of VRAM capable of local neural net inference. The Logitech webcam is motorized and has pan/tilt capabilities making it very appropriate as a face tracking webcam.
Data collection
I collected training data both through in-house methods and using an open source dataset. The in-house data collection basically consisted of me recording videos of people in front of a camera, capturing frames at fixed intervals, and labeling the faces with bounding boxes. Rather than label these bounding boxes by hand, I used OpenCV’s Haar Cascades face detector to automatically draw bounding boxes on the images. The Haar Cascades classifiers are machine learning models trained on hand engineered features to detect faces. While they aren’t perfect and there is fair amount errors in my data, they work well enough as training data.
The dataset was then supplemented with the Face Detection Data Set and Benchmark (FDDB) [1], which is a collection of 2,845 images with the faces labeled with bounding box coordinates. Altogether, I ended up with a dataset of 14,664 images. Here are examples from both the FDDB dataset and the in-house dataset:

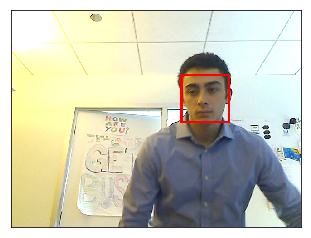
Data preprocessing
The training data was augmented through standard image augmentation methods:
- Random scale up to 50% of the original image size
- Random rotation up to 5 degrees in either direction
- Random flip about the y-axis
- Random HSV shift
- Random contrast multiplier
- Random brightness multiplier
Model training
While deciding on a model architecture, inference speed was the biggest concern since real-time inference was one of the main objectives of this project. I went with You Only Look Once (YOLO) [2], the current state-of-the-art real-time object detection framework. YOLO treats object detection as a regression problem where the bounding box coordinates for each class are predicted through a single network. Previous object detection frameworks used a dual network approach where one network proposed regions of interest and the other network classified objects within those regions. Instead, YOLO uses a single network predicting the proposal regions and detected classes in a single pass. Model training was done using the “darknet” library, a custom C/CUDA library developed by the founders of YOLO.
Robotic deployment
Since darknet is custom library, there was no existing interface between this library and Robot Operating System (ROS). I wrote an ROS wrapper, darknet_ros found here: darknet_ros, that links the C++ ROS libraries with the C/CUDA code of the YOLO framework. Long story short, darknet_ros creates an ROS node that captures images from the webcam and sends them to YOLO. YOLO does the model inference and sends the results back to the ROS node.
To get the camera to track detected faces, I created a simple algorithm that uses the bounding box coordinates from the darknet_ros node to determine actions. A boundary zone is drawn in the middle of the field of view and if the center of the bounding box coordinates move outside this boundary, a pan/tilt command will be sent to the camera’s motor to recenter. Also, since the camera has maximum rotation angle, the robot itself will rotate using its mobile base if the camera nears it maximum angle of rotation. This was a non-trivial challenge as the robotic system has to keep track of the relative positions of the three joints: the pan, tilt, and mobile base joints.
Here’s a video of the system in action: video
![]()
Deployed on the integrated GPU of the Jetson TX1, I was only able to achieve up to 10 FPS, which was far short of my goal of 30 FPS. The bottleneck was due to the inference time of the object detection model. More than just an aesthetic issue, predictions were only being made 10 times per second and so the robotic system could also only make decisions at that interval.
To fill the gap between these intervals, I used a computer vision technique, template matching, to “guess” where the face was likely to be until the object detector gave the next prediction. I made the assumption that between each detection interval, a face can only move so far away from its original location. By simply looking at how the pixel values change from frame to frame, I can make a pretty good guess where the face has moved to.
Template matching is a computer vision technique that works by taking a template image and scanning another image with that template and finding the location where the pixels match up the most. In my case, the template image was the cropped image of the face that I extracted from the bounding box predictions of the object detector, and I scanned the next frame to find the location where the face was most likely to appear. I simplify even further by only scanning a limited region around the detected face.
The 30 FPS system works like this:
- The object detector predicts the bounding box coordinates of the detected face every other third frame.
- For the remaining frames, a cropped image of the face from the bounding box is used as a template for the template matching algorithm.
- The system relies on the template matching predictions until the next prediction arrives from the object detector.
Here’s a video of the improved 30 FPS system: video
You’ll notice the template matching makes the bounding box a little less stable but detection speed is noticeably faster. The video also shows my name being recognized. This was a later addition that I made while experimenting with facial recognition. I trained a neural net classifier to recognize faces and ran the model on the cropped image of detected faces.
Future improvements
From an inference speed standpoint, certainly better hardware or a more efficient model would increase the FPS and get rid of the dependence on template matching, however there may be a more fundamental issue at play here. When humans recognize an object, we don’t have to keep recognizing that same object every instant in time, rather we keep a memory of that object and make assumptions of where that object will be in the near future. Similarly, adding a temporal component to the object detection neural net framework could drastically improve real-time detection capabilities. With the advancements in recurrent neural networks on temporal data such as text and audio, it would be interesting to see how they could be applied to computer vision problems like this.
Concerning to the tracking algorithm, instead of relying on a rules based approach to controlling the camera motor, reinforcement learning could be used to train a model to control the motor. Such a model would receive a reward if the detected face was centered in a field of view and the actions it could take would be left-right, up-down commands.
As the field of robotics becomes more and more intertwined with the field of machine learning, it will be very exciting to see many of these problems and greater problems being solved in the near future.
If you have any questions or suggestions please feel free to contact me.
Citations
[1] Vidit Jain and Erik Learned-Miller. FDDB: A Benchmark for Face Detection in Unconstrained Settings. Technical Report UM-CS-2010-009, Dept. of Computer Science, University of Massachusetts, Amherst. 2010.
[2] J. Redmon and A. Farhadi. YOLO9000: Better, Faster, Stronger. arXiv preprint arXiv:1612.08242, 2016.