Abstractive Text Summarization for Title Generation
Full code for this post can be found here
Contents
- Overview
- Dataset
- Data preprocessing
- Model architecture
- Supervised learning
- Reinforcement learning
- Evaluation
- Future improvements
Overview
Objectives:
- Train a seq2seq RNN to generate novel titles conditioned on document abstracts
- Improve readability and richness of text generation using reinforcement learning.
Recurrent neural network (RNN) architectures have made great strides in solving natural language understanding tasks such as document classification and named entity recognition, but it has been the sequence-to-sequence variants that have allowed researchers to extend the success of RNNs to much more challenging NLP problems such as machine translation and text summarization. In this post, I’ll be exploring the task of text summarization, specifically for generating titles from document abstracts. Whereas many previous works have focused on the task of generating multi-sentenced summaries of documents, I’ve simplified the task by only generating short, single sentence titles. I’ve simplified the task for the purposes of quick experimentation of model architectures and hyperparameter tuning, although all of the concepts and techniques discussed in the post are transferrable to the multi-sentence problem.
I’ll also consider two formulations of this task: 1) a supervised learning approach that maximizes the likelihood of generated titles, 2) and a reinforcement learning approach that maximizes reward based on a number of discrete, non-differentiable metrics. I’ll evaluate the two approaches using quantitative and qualitative metrics and discuss areas for improvement.
Dataset
I chose to use the PubMed dataset because of its availability, size, and suitability for this task. The PubMed dataset is an open-source dataset of over 26 million citations for medical literature, and contains, among other meta-data, titles and abstracts for each document. On average, the abstracts contain about 200 words and the titles contain around 20 words. The dataset that I extracted consists of 14 million documents abstract-title pairs. Here are some examples:

Text generation models require large amounts of data to train, making the size of PubMed very advantageous. Also, the dataset represents medical research collected across all medical domains from the past century, which makes it very applicable to many real-world applications in the medical industry. However, because the dataset is highly domain specific, the vocabulary consists of very technical terms, which not only makes it unsuitable for transfer learning but also makes building a model that can encapsulate the full vocabulary very difficult.
Data preprocessing
Each abstract and title is truncated to 150 words and 20 words respectively and are lowercased. All non-alphanumeric characters, except for periods, are removed and the vocabulary is limited to the 30,000 most common words. All unknown words are represented singularly using an “UNK” token, and an “EOS” (end of sequence) token is appended to each abstract and title.
Model architecture
The sequence-to-sequence (seq2seq) encoder-decoder architecture is the most prominently used framework for abstractive text summarization and consists of an RNN that reads and encodes the source document into a vector representation, and a separate RNN that decodes the dense representation into a sequence of words based on a probability distribution.
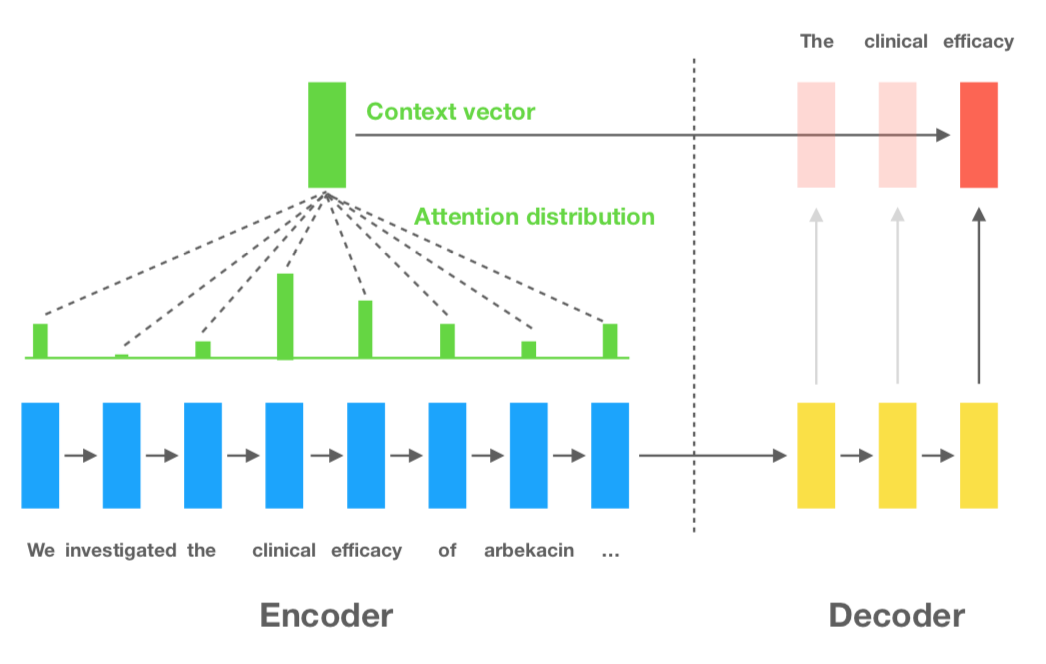
Attention mechanisms have been shown to enhance the performance of seq2seq architectures across almost all tasks. Specifically, attention mechanisms allow the decoder to access the outputs of the encoder for each generated word and create a weighted representation of the encoder outputs based on the current context of the decoder step. In other words, each word that is generated by the decoder will be conditioned on a unique weighted representation of the source words. It turns out that this attention computation is extremely inefficient and memory intensive during back propagation making it impractical when dealing with long documents. To mitigate this issue, I’ll simplify the attention mechanism by only calculating the weighted representation of the encoder outputs once and conditioning each generated word on this single dense vector. My tests revealed that this simplified attention showed no decrease in performance and led to faster convergence and less memory usage.
I use Gated Recurrent Units (GRUs) with 2 layers for my encoder and decoder RNNs and set the hidden size to 256. I also tie the embedding weights to the output projection so that the decoder projects a distribution over the high-dimensional, vocabulary space using the embeddings matrix rather than using an additional weights matrix. This significantly reduces the number of parameters in the network and leads to faster convergence with no effect on performance.
Supervised learning approach
The supervised learning formulation seeks to generate titles that maximize the likelihood distribution of the data by minimizing the negative log probabilities of the target words. Each word generated is compared to the actual word of the same time step and a loss is calculated that approaches zero when the generated word is the same as the actual word. Another way to think of this formulation is that the perfect model will generate a title that appears like the rest of the data. Maximum likelihood optimization simply aims to replicate the behavior and characteristics exhibited by a certain dataset. The optimization minimizes the following loss function:
One interesting consequence of this formulation is that the decoder RNN essentially becomes a language model that produces “title-like” sequences. Even if the generated title is incorrect, the decoder will usually generate a coherent title that appears correct. The biggest disadvantage with this formulation, however, is that a “correct” title does not necessarily have to be the one given by the title. In fact, there could be multiple titles, or even better titles, that best reflect the content of the document but since the target title is treated as the sole solution, the optimization is significantly hindered.
Reinforcement learning approach
The reinforcement learning formulation seeks to generate titles that maximize a discrete metric, defined by a reward function, through policy learning. A policy is function that describes what actions an agent will take given a state in an environment and finding the optimal policy will result in an agent that takes actions that maximizes possible reward. In this case, the policy is simply the seq2seq model and actions are the words that the model can generate at each time step. Rather than trying to reproduce the target title, as in the case of the supervised learning approach, the policy is trained only to consider maximizing reward.
I define a reward function that consists of three metrics:
- The ROUGE metric measures the recall of the n-gram overlap between the generated titles and the target titles. ROUGE is a common metric used to evaluate text generation systems so it makes sense to use it directly in optimizing the model. Since ROUGE is measuring overlap, it tends to favor longer sequences with a variety of words. This is good characteristic as longer titles will lead to richer and more informative content. Specifically, I use ROUGE-L, which measures the longest common substring between the generated title and the target title, to produce a reward value between 0 and 1.
- One consequence of ROUGE is that it does not consider the coherency of the generated titles and tends to lead to titles that contain relevant words but do not make sense as a title. To combat this, I trained a coherency classifier that predicts whether or not a given title is coherent or not. In order to train this classifier, I used the existing titles from the dataset as positive examples, and used augmentation techniques such as word shuffling, repetition, and inclusion, to create negative examples of those same titles. The classifier is an RNN with a dense layer conditioned on the last hidden state of the RNN. I trained this model to achieve at least 95% accuracy and used it to read generated titles and produce a reward value between 0 and 1.
- One major flaw of the supervised learning approach is that when the model is unsure of what word to generate next, it tends to fall back on predicting the “UNK” token since it has the most ambiguous semantic meaning of all of the words in the vocabulary. This, however, provides no value in terms of readability. I add a simple reward metric that measures the ratio of the generated sentence that does not contain “UNK” tokens, which produces a reward value between 0 and 1.
I combine these three reward metrics into a single reward using the following formula:
The model is trained using self-critical policy gradient algorithm first introduced by [1]. Instead of using a separate baseline model to decrease the variance of the reward propagation, the seq2seq model generates two titles using sampling and greedy selection and scales the gradients using the difference between the rewards of both titles. The policy gradient then minimizes the following loss function:
Where the term under the sum is the log probability of the sampled title. To prevent the “cold start” problem associated with training reinforcement learning models, I initialized the seq2seq model using the best weights from the supervised learning model.
Evaluation
Below I compare the results of the supervised learning approach and the reinforcement learning approach using the ROUGE F1 metric.
| Model | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| SL | 0.428 | 0.183 | 0.374 |
| RL | 0.480 | 0.209 | 0.414 |
** SL = supervised learning, RL = reinforcement learning
The reinforcement model outperforms the supervised learning model on ROUGE-1,2,L but this isn’t that surprising since the reinforcement learning model was optimized directly on the ROUGE metric. What is more interesting is to look at the some example titles generated by both models:

Here we can see that the reinforcement model tends to produce richer titles by adding leading phrases such as “the relationship of” and “the processing of”. These subtle phrases add a slightly more natural sounding effect than the supervised learning model and was likely encouraged by the coherency reward. The titles generated by the reinforcement learning model also tend to be slightly longer, which was likely encouraged by the ROUGE reward since longer titles tend to have a higher amount of overlap with the actual titles than shorter ones.

The reinforcement learning model is also less prone to relying on the “UNK” token when it is unsure of what word to generate next. The two examples above show the supervised learning model “giving up” and producing a succession of “UNK” tokens whereas the reinforcement model, while still generating a few “UNK” tokens, is much more robust. The “UNK” reward is the obvious culprit but the coherency and ROUGE rewards could have also contributed to this result since “UNK” tokens would have negatively effected their rewards.
Future improvements
The problem with the supervised learning formulation is that the optimization is biased to the actual titles. The reinforcement learning formulation mitigates this problem by rewarding based on the ROUGE metric, but this ends up still being biased to the actual titles as well, just not as much. A true unbiased optimization strategy would be one that measures generated titles based on semantic relevance to the document as well as the amount of informative content contained. One solution that I propose is to reformulate the problem as a reading comprehension task where a set of questions about the document must be answerable using the generated title alone. This would be especially effective for generating multi-sentence summaries that capture the most important facts of a document. This approach would be adaptable to multiple domains by simply changing the questions used during optimization.
Another problem that remained unsolved by the reinforcement learning formulation was the readability of generated titles. The coherency reward led to titles that were within reason but still far from being truly indistinguishable from true language. With the recent success of Generative Adversarial Networks (GANs) in producing realistic images, a similar approach could be used where the coherency classifier is trained as the discriminator network that decides whether the generated title is real or not. Rather than rely on rules-based text shuffling and replacement methods, meant to simulate common mistakes made by the generative model, to train the classifier, the classifier would adapt directly to the model’s imperfections.
If you have any questions or suggestions please feel free to contact me.
Citations
[1] Steven J Rennie, Etienne Marcheret, Youssef Mroueh, Jarret Ross, and Vaibhava Goel. 2016. Self-critical sequence training for image captioning. arXiv preprint arXiv:1612.00563.